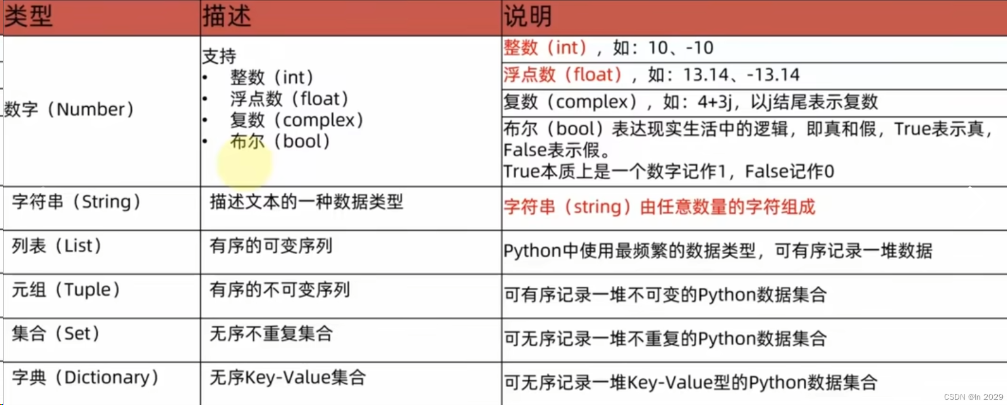
第一章 字面量 定义:在代码中,被写下来的固定的值,称之为字面量。 Python有六种常用的数据类型 注释 定义:对代码进行解释说明的文字 作用:对代码进行解释说明,注释不会被执行,只是用来增强程序的可读性 语法:单行注释:以#开头,#右边的所有文字都会当作说明 多行注释:以一对三个双引号引起来 变量 定义:程序运行时用来储存计算结果或表示值的抽象概念。简单来说变量是存储数据用的 变量的定义格式:变量名 = 值 在Python中,一个变量名可以定义多次,定义的值会覆盖掉之前定义的值 数据类型 可以通过type(变量),查看变量的数据类型,type(变量)的返回值就是该数据的数据类型
数据类型转换 数据类型之间,在特定的场景下,是可以相互转换的,如字符串转数字,数字转字符串等。 常见的转换语句 1 2 3 4 5 6 """ 这三个语句都是带有结果的(返回值) """ int (x) float (x) str (x)
标识符 定义:在编程的时候所使用的一系列名字,用于给变量、类、方法等命名。 命名规则:内容限定:只允许出现:英文、中文(不推荐使用)、数字(不可以用在开头)、下划线(__)大小写敏感:大小写可以完全区分不可使用关键字:如int、float、str等 命名规范:见名知意、下划线命名法(多个单词组合变量名,需使用下划线做分隔)、英文字母全小写。 运算符 运算符 描述 实例 + 加 a+b=30 — 减 a-b=-10 * 乘 a*b=200 / 除(含小数) a/b=0.5 // 取整数 a//b=0 % 取余 a%b=10 ** 指数 a**b输出结果为10的20次方
运算符 描述 实例 = 赋值 a=10 += 加法赋值 a+=10等效于a=a+10 -= 减法赋值 a-=10等效于a=a-10 *= 乘法赋值 a=10等效于a=a 10 /= 除法赋值 a/=10等效于a=a/10 //= 取整除赋值 a//=10等效于a=a//10 %= 取余赋值 a%=10等效于a=a%10 **= 指数赋值 a=10等效于a=a 10
字符串 定义方法 单引号定义法1 2 3 str1='hello world' str2 = 'It\'s a cat' str3 = 'He said: "Hello"'
双引号定义法1 2 3 str4="hello world" str5 = "It's a cat" str6 = "He said: \"Hello\""
三引号定义法1 2 3 4 5 6 7 8 9 10 11 12 13 14 """ 三引号的特点是: 1. 支持直接换行(无需用 \n 转义),保留文本的原始格式 2. 内部可以自由包含单引号和双引号,无需额外转义 3. 常用来定义多行文本(如文档字符串、SQL 语句、HTML 代码等) """ pstr7='''hello world''' str8 = """It's a cat""" str9 = '''It's a cat''' str10 = """ He said: "Hello world!" """
拼接 字符串支架可以通过+号进行拼接1 2 str11 = "hello" + " " + "world" print (str11)
格式化 格式化语法: “%占位符 “ %(变量1,变量2,变量3) 常用占位符 语法:f”字符串{变量1}字符串{变量2}字符串” 快速格式化不关注类型,也不能精度控制,只适合没有其他要求时快速使用 字符串格式化的精度控制 可以通过使用辅助符号”m,n”来控制数据的宽度和精度m表示数据的最小宽度,要求必须是数字,设置的宽度小于数字自身时不生效 n表示小数点的精度,要求是数字,会进行四舍五入 这是一个设置宽度为2位的数字:123
1 2 3 4 5 6 7 8 a=123 b=123.456 c=111.111 print ("这是一个设置宽度为2位的数字:%2d" %a)print ("这是一个宽度为五位的数字:%5d" %a)print ("这是一个有两位小数的数字:%0.2f" %c)print ("这是一个宽度为五位,且有两位小数的数字:%5.2f" %b)print (f" a={a} \n b={b} \n c={c} " )
输入函数 语法:input(“提示信息”) 功能:用于接收用户输入的信息 返回值:无论用户输入哪种类型的信息,默认都是字符串型 示例: 1 2 name=input ("请输入您的姓名:" ) print (f"您的姓名是:{name} " )
第二章 布尔类型和比较运算符 布尔类型:只有两个值True和False 布尔值可以和数字进行运算,True等价于1,False等价于0 1 2 3 4 t=True f=False print (t+1 ) print (f+1 )
运算符 描述 实例 == 判断内容是否相等,满足为True,不满足为False 如a=5,b=3,则(a==b)为False != 判断内容是否不相等,满足为True,不满足为False 如a=5,b=3,则(a!=b)为True > 判断运算符左侧内容是否大于右侧,满足为True,不满足为False 如a=5,b=3,则(a > b)为True < 判断运算符左侧内容是否小于右侧,满足为True,不满足为False 如a=5,b=3,则(a < b)为False >= 判断运算符左侧内容是否大于等于右侧,满足为True,不满足为False 如a=5,b=3,则(a>=b)为True <= 判断运算符左侧内容是否小于等于右侧,满足为True,不满足为False 如a=5,b=3,则(a<=b)为False
if语句 判断条件的结果必须是布尔类型;不要忘记判断条件后的:冒号;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 """ 当满足if或elif语句的条件时,会执行if语句下的代码块; 执行结束后会直接跳出该if块,不会执行其他的if语句或elif语句 当所有if和elif的条件均不满足时,会执行else语句下的代码块; 如果没有else语句,且所有条件均不满足时,程序会直接跳过if语句,继续执行后续代码。 """ if 条件表达式1 : 语句块1 elif 条件表达式2 : 语句块2 elif 条件表达式3 : 语句块3 else : 语句块4
嵌套if语句 定义:在一个if语句块中,再嵌套一个if语句 语法格式 1 2 3 4 5 6 7 8 9 10 if 条件表达式1 : 语句块1 if 条件表达式2 : 语句块2 else : 语句块3 else : 语句块4
嵌套判断语句可以用于多条件、多层次的逻辑判断;
第三章 while循环 语法格式 1 2 3 4 5 6 while 条件表达式: 执行语句1 执行语句2 执行语句3 执行语句4 ……
条件需提供布尔类型结果,True则执行,False则跳过;空格缩进需严格执行;设置好循环终止条件﹐否则将无限循环。
嵌套循环 定义:在一个while循环体内,再嵌套一个while循环 1 2 3 4 5 while 条件表达式1 : 执行语句1 while 条件表达式2 : 执行语句2 执行语句3
1 2 3 4 5 6 7 8 9 10 11 12 a=1 while a<5 : print ("上部while循环,此时a的值为:" ,a) a+=1 while a<3 : print ("内部while循环,此时a的值为:" ,a) a+=1 print ("底部while循环,此时a的值为:" ,a) print ("循环结束,此时a的值为:" ,a)
1 2 3 4 5 6 7 8 上部while 循环,此时a的值为: 1 内部while 循环,此时a的值为: 2 底部while 循环,此时a的值为: 3 上部while 循环,此时a的值为: 3 底部while 循环,此时a的值为: 4 上部while 循环,此时a的值为: 4 底部while 循环,此时a的值为: 5 循环结束,此时a的值为: 5
补充知识点 在python中使用print函数默认换行,该如何实现输出不换行呢? 1 2 print ("hello" ,end='' )print ("world" ,end='' )
1 2 3 4 5 6 7 8 9 i=1 while i <= 9 : j = 1 while j <= i: print (f"{j} *{i} ={i*j} " ,end="\t" ) j+=1 i+=1 print ()
for循环 使用方法 1 2 3 4 5 6 name1 = "itheima is a brand of itcast" i = 0 for x in name1: if x == 'a' : i+=1 print ("一共有%d个a" %i)
for循环中的变量,只在for循环中生效,循环结束后,变量就会被销毁
但这种限定是编程规范的限定,在Python中非强制限定;不遵守也能正常运行,但是不建议这样做;如需访问临时变量,可以预先在循环外定义它
range函数 定义 :用于生成一个整数序列语法格式 语法一:range(num) 语法二:range(start,stop) 语法三:range(start,stop,step) 解释 语法一表示从0开始,到num结束,不包含num 语法二表示从start开始,到stop结束,不包含stop 语法三表示从start开始,到stop结束,不包含stop,步长为step 1 2 3 4 5 6 7 8 9 10 11 12 for x in range (10 ): print (x) for x in range (5 ,10 ): print (x) for x in range (5 ,10 ,2 ): print (x)
for循环嵌套 定义:在一个for循环体内,再嵌套一个for循环 语法格式for循环和while循环可以相互嵌套使用
1 2 3 4 for 变量1 in 序列1 : 循环体1 for 变量2 in 序列2 : 循环体2
continue和break continue和break在for和while循环中作用一致;
第四章 函数是什么 函数是组织好的,可重复使用的,用来实现特定功能的代码块 函数的好处实现特定功能 可供随时随地重复利用 提高代码的复用性,减少重复代码,提高代码的可维护性 提高开发效率。 定义语法 当没有参数时,参数列表可以省略,但是括号不能省略 当函数有返回值时,return语句必须写,且必须返回一个值 当函数没有返回值时,return语句可以省略1 2 3 def 函数名 (参数1 ,参数2 ,参数3 ): 函数体 return 返回值
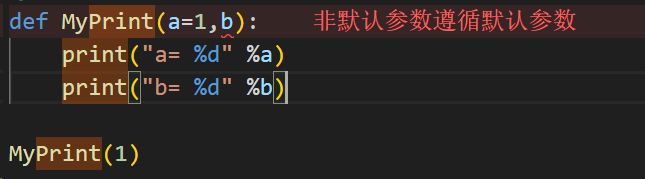
传入参数 传入参数的定义形式参数:定义函数时,括号中的参数,称为形式参数实际参数:调用函数时,括号中的参数,称为实际参数 传入参数的类型位置参数最常见的参数类型,必须按照定义的顺序传递 例如:def func(a, b): … 调用时 func(1, 2) 关键字参数通过参数名指定值,不依赖顺序 例如:func(a=1, b=2) 或 func(b=2, a=1) 默认参数定义函数时指定默认值,调用时可省略 默认参数以后的参数必须定义为默认参数 例如:def func(a, b=2): … 调用时 func(1) 等效于 func(1, 2) 可变参数接收任意数量的位置参数,用 *args 表示 例如:def func(*args): … 调用时 func(1, 2, 3),args 会成为元组 (1, 2, 3)1 2 3 4 5 6 7 def add (x,y ): return x + y print (add(1 ,2 ))""" 输出结果: 3 """
1 2 3 4 5 6 7 8 9 10 def MyPrint (a,b ): print ("a= %d" %a) print ("b= %d" %b) MyPrint(b=1 ,a=2 ) """ 输出结果: a= 2 b= 1 """
1 2 3 4 5 6 7 8 9 10 def MyPrint (a=1 ,b=2 ): print ("a= %d" %a) print ("b= %d" %b) MyPrint(1 ) """ 输出结果: a= 1 b= 2 """
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def MyPrint (* args ): for x in args: print (x) print (args) MyPrint(1 ,2 ,3 ,9 ,8 ,7 ) """ 输出结果: 1 2 3 9 8 7 (1, 2, 3, 9, 8, 7) """
返回值 函数的返回值,通过return关键字返回 当函数没有返回值时,默认返回None 1 2 3 4 5 6 7 8 9 10 11 12 13 def MyAdd (a,b ): print (a) print (b) a=MyAdd(1 ,2 ) print (a)""" 输出结果: 1 2 None """
None类型 None是Python的一个特殊类型,用于表示空值或不存在的情况它是一个唯一的对象,在内存中只有一个实例 可以将None赋值给变量,用于表示变量当前没有值 不使用return语句返回时,函数默认返回None 使用场景: 函数说明文档 作用:对函数的参数,作用返回类型等进行说明 语法格式1 2 3 4 5 6 7 8 9 def 函数名 (参数x,参数y ): """ 函数说明文档 :param 参数x: 参数x的说明 :param 参数y: 参数y的说明 :return: 返回x+y的值 """ 函数体 return x + y
函数嵌套调用 定义:在一个函数中调用另一个函数 执行流程: 函数A中执行到调用函数B的语句,会将函数B全部执行完成后,继续执行函数A的剩余内容。 变量在函数中的作用域 1 2 3 4 5 6 def myfunction (x,y ): global c c = x+y myfunction(1 ,2 ) print (c)
第五章 数据容器 定义:一种可以容纳多份数据的数据类型,容纳的每一份数据称之为元素,可以是任意类型的数据,如字符串、数字、布尔等。 容器的种类:list(列表) tuple(元组) str(字符串) dict(字典) set(集合) 列表 基本语法: 1 2 3 4 5 a = [元素1 ,元素2 ,元素3 , ... ] b = [] c = list ()
列表中的元素可以是任意类型,如字符串、数字、布尔,甚至元素也可以是列表。 1 2 3 list = ['h' ,'s' ,'z' ,['c' ,'p' ,'y' ],1 ]print (list )print (type (list ))
特点 列表的特点:列表是有序的,可变的数据类型 列表中的元素可以重复 列表的元素可以改变 列表能容纳多个元素(上限为2**63-1) 列表的元素可以进行排序 列表中能够容纳不同的数据类型 下标索引 列表的索引从0开始,索引可以使用正数和负数。正数索引:从左往右,第一个元素的索引为0,第二个元素的索引为1,以此类推。负数索引:从右往左,最后一个元素的索引为-1,倒数第二个元素的索引为-2,以此类推。 常用操作 编号 使用方式 作用 1 列表.append(元素) 向列表追加一个元素 2 列表.extend(元素) 将数据内容依次取出,再追加到列表尾部 3 列表.insert(下标,元素) 在指定下标处,插入指定的元素 4 del 列表(下标) 删除列表指定下标元素 5 列表.pop(下标) 删除列表制定下标元素 6 列表.remove(元素) 从前往后,删除此元素第一个匹配项 7 列表.clear() 清空列表 8 列表.count(元素) 统计此元素在列表中出现的次数 9 列表.index(元素) 查找指定元素在列表的下标,找不到报错 10 len(列表) 统计容器内有多少元素
在Python中,如果将函数定义为class(类)的成员,那么函数会称之为:方法;方法和函数功能一样,有传入参数,有返回值,只是方法的使用格式不同。
1. 查找元素下标 功能:查找指定元素在列表的下标,如果找不到则报错ValueError 语法:列表.index(元素); 2. 修改元素 语法: 列表[下标]=值
可以直接对指定下标(正向、反向下标均可)的值进行重新赋值(修改)1 2 3 list = ['h' ,'s' ,'z' ,['c' ,'p' ,'y' ],1 ]list [0 ] = 'a' print (list )
3. 删除元素 语法1: del列表[下标] 语法2: 列表.pop(下标) 4. 插入元素 功能: 在指定位置插入元素 语法: 列表.insert(下标,元素) 5. 追加元素 语法1: 列表.append(元素),将指定元素,追加到列表的尾部 语法2: 列表.extend(其它数据容器),将其它数据容器的内容取出,依次追加到列表尾部 1 2 list .append('多啦A萌' )list .extend(['很' ,'可' ,'爱' ])
6. 删除出现的第一个元素 语法:列表.remove(元素) 删除某元素在列表中的第一个匹配项 7. 清空列表 8. 统计元素数量 统计某元素在列表内的数量 语法:列表.count(元素) 9. 统计元素总数量 语法: len(列表)
以上代码块中的list均代指数据类型为列表的变量名。
遍历列表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 def list_while (): list = ['a' ,'b' ,'c' ,'d' ] num = 0 while num< len (list ): print (list [num]) num+=1 list_while() def list_for (): list = ['a' , 'b' , 'c' , 'd' ] for x in list : print (str (x)) list_for()
元组 定义:一种有序的数据类型,元素不可修改,元素可以重复的数据容器。 与列表的主要区别是:元组中的元素不能修改(可以修改内部list的内部元素)。 元组的操作 编号 使用方式 作用 1 元组.index(元素) 查找指定元素在元组的下标,找不到报错 2 元组.count(元素) 统计此元素在元组中出现的次数 3 len(元组) 统计容器内有多少元素
1 2 3 tuple .index('h' )tuple .count('h' )len (tuple )
1 2 3 4 5 6 7 8 9 index = 0 while index < len (t1): print (f"while:元组的元素有: {t1[index]} " ) index += 1 for element in t1: print (f"for:元组的元素有: {element} " )
字符串 下标索引 与列表一样,索引可以使用正数和负数,整数从0开始,负数从-1开始。 特点 字符串的特点:字符串是只读的,不能修改 字符串的每一部分都是一个字符 字符串是有序的,每个字符都有一个下标 字符串是可以拼接的,拼接的结果是一个新的字符串 字符串是可以比较的,比较的结果是一个布尔值 比较 字符串之间比较大小是按位比较,也就是一位位的进行对比,只要一位不相同,则不会继续比较下去。 常用操作 编号 操作 说明 1 字符串[下标] 根据下标索引取出特定位置的字符 2 字符串.index(字符串) 查找给定字符的第一个匹配项的下标 3 字符串.replace(字符串1,字符串2) 将所以字符串1替换为字符串2,并不会修改原字符串,是返回一个新的字符串 4 字符串.split(字符串) 根据给定的字符分隔字符串,不会修改原字符串,是返回一个新的字符串 5 字符串.strip()或字符串.strip(字符串) 移除首尾的空格和换行符或者指定字符串 6 字符串.count(字符串) 统计字符串内某字符串的出现次数 7 len(字符串) 统计字符串的字符个数
1.查找下标 根据下标索引取出特定位置的字符
1 2 3 value = my_str.index( "and" ) print (f"在字符串{my_str} 中查找and,其起始下标是: {value} " )
2.字符串替换 将所以字符串1替换为字符串2,并不会修改原字符串,是返回一个新的字符串
1 2 3 4 my_str = "hello and hello" new_str = my_str.replace('hello' , 'world' ) print (new_str)print (my_str)
3.字符串分隔 根据给定的字符分隔字符串,不会修改原字符串,是返回一个新的字符串
1 2 3 4 my_str = "hello and hello" new_str = my_str.split('and' ) print (new_str)print (my_str)
4.字符串移除 移除首尾的空格和换行符或者指定字符串
1 2 3 4 my_str = " hello and hello " new_str = my_str.strip() print (new_str)print (my_str)
5.字符串统计 统计字符串内某字符串的出现次数
1 2 3 4 my_str = "hello and hello" new_str = my_str.count('hello' ) print (new_str)print (my_str)
以上代码块中的str均代指数据类型为字符串的变量名。
遍历字符串 1 2 3 4 5 6 7 str = "itheima itcast boxuegu" for x in str : print (f"for循环遍历字符串{x} " ) index = 0 while index<len (str ): print (f"while循环遍历字符串{str [index]} " ) index+=1
序列 定义:指内容连续,有序,元素可以重复且可以使用下标索引的一类数据容器 序列是一类数据容器,列表、元组、字符串都是序列
切片意思是从一个序列中,取出一个子序列
语法:[开始索引:结束索引:步长] 表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列 说明:开始索引:表示从哪个位置开始取,默认是0 结束索引:表示到哪个位置结束取,默认是序列的长度 步长:表示每次取的间隔,默认是1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 list = [0 ,1 ,2 ,3 ,4 ,5 ,6 ]print (list [1 :4 :1 ])tuple = (0 ,1 ,2 ,3 ,4 ,5 ,6 )print (tuple [::])str = '0123456' print (str [::2 ])print (str [::-1 ])print (list [3 :1 :-1 ])print (tuple [::-2 ])
集合 定义:指内容不连续,无序,元素不可以重复的一类数据容器 集合是无序的,故集合不支持下标索引访问 1 2 3 4 5 6 {1 ,2 ,3 ,4 ,5 } set = {1 ,2 ,3 ,4 ,5 }Set1 = set ()
特点 集合是无序的,故不支持索引访问 集合不允许重复元素 集合可以容纳不同类型的数据 集合可以修改元素 集合支持for循环,不支持while循环 常用操作 编号 操作 说明 1 集合.add(元素) 集合内添加一个元素 2 集合.remove(元素) 移除集合内指定的元素 3 集合.pop() 从集合中随机取出一个元素 4 集合.clear() 将集合清空 5 集合1.difference(集合2) 得到一个新集合,内含2个集合的差集 原有的2个集合内容不变 6 集合1.difference_update(集合2) 在集合1中,删除集合2中存在的元素 集合1被修改,集合2不变 7 集合1.union(集合2) 得到1个新集合,内含2个集合的全部元素 原有的2个集合内容不变 8 len(集合) 得到一个记录集合元素数量的数字
集合不属于序列类,故常用操作与前面的列表等数据容器差异较大 1.添加元素 语法:集合.add(元素)。将指定元素,添加到集合内。 结果:集合本身被修改,添加了新元素。 2.删除元素 语法:集合.remove(元素),将指定元素,从集合内移除。 结果:集合本身被修改,移除了元素。 3.随机取出元素 语法∶集合.pop()功能,从集合中随机取出一个元素。 结果:会得到一个元素的结果。同时集合本身被修改,元素被移除。 1 2 3 4 5 6 7 8 9 set = {1 ,2 ,6 ,8 ,4 ,6 ,5 }print (set )a=set .pop() print (a)set .add(a)print (set )print (set .pop())print (set )
4. 清空集合 5. 获取集合的差集 语法∶集合1.difference(集合2) 功能:取出集合1和集合2的差集(集合1有而集合2没有的) 结果:得到一个新集合,集合1和集合2不变。 1 2 3 4 5 6 set1 = {1 ,2 ,3 ,4 ,5 } set2 = {3 ,4 ,5 ,6 ,7 } set3 = set1.difference(set2) print (set3)print (set1)print (set2)
6.消除两个集合的差集 语法:集合1.difference_update(集合2) 功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素。 结果:集合1被修改,集合2不变 1 2 3 4 5 set1 = {1 ,2 ,3 ,4 ,5 } set2 = {3 ,4 ,5 ,6 ,7 } set1.difference_update(set2) print (set1)print (set2)
7.合并两个集合 语法:集合1.union(集合2) 功能:将集合1和集合2的全部元素,合并到一个新集合内。 结果:得到一个新集合,集合1和集合2不变。 1 2 3 4 5 6 set1 = {1 ,2 ,3 ,4 ,5 } set2 = {3 ,4 ,5 ,6 ,7 } set3 = set1.union(set2) print (set3)print (set1)print (set2)
遍历集合 1 2 3 4 for x in set1: print (x)
字典 定义字典同样是使用{},不过存储的元素是一个个键值对
1 2 3 4 5 6 7 {key:vaule,key:value,......,key:value} my_dicty = {key:value,key:value,......,key:value} my_dicty = {} my_dicty = dict ()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 my_dict1 = {'王' :99 ,'林' :88 ,'周' :99 } my_dict2 = {} my_dict3 = dict () print (f"字典1的内容是:{my_dict1} ,类型:{type (my_dict1)} " )print (f"字典2的内容是:{my_dict2} ,类型:{type (my_dict2)} " )print (f"字典3的内容是:{my_dict3} ,类型:{type (my_dict3)} " )my_dict4 = {'王' :99 ,'王' :88 } print (f"字典4重复key的内容是:{my_dict4} " )print (my_dict1['王' ])subject = { '王' :{ '语文' :77 , '数学' :66 , '英语' :33 },'周' :{ '语文' : 88 , '数学' : 86 , '英语' : 55 },'林' :{ '语文' : 99 , '数学' : 96 , '英语' : 66 } } print (f"学生的考试信息:{subject} " )print (subject['王' ]['语文' ])
键值对的Key和Value可以是任意类型(Key不可为字典) 字典内Key不允许重复,重复添加等同于覆盖原有数据 字典不可用下标索引,而是通过Key检索Value 操作 编号 操作 说明 1 字符串[下标] 根据下标索引取出特定位置字符 2 字符串.index(字符串) 查找给定字符的第一个匹配项的下标 3 字符串.replace(字符串1,字符串2) 将字符串内的全部字符串1,替换为字 符串2 不会修改原字符串,而是得到一个新的 4 字符串.split(字符串) 按照给定字符串,对字符串进行分隔 不会修改原字符串,而是得到一个新的 列表 5 字符串.strip() 字符串.strip(字符串) 移除首尾的空格和换行符或指定字符串 6 字符串.count(字符串) 统计字符串内某字符串的出现次数 7 len(字符串) 统计字符串的字符个数
新增元素 语法:字典[Key]= Value, 结果:字典被修改,新增了元素 1 2 3 my_dict1['张' ]=100 print (my_dict1)
更新元素 语法:字典[Key] = value 结果:字典被修改,元素被更新 注意:字典Key不可以重复,所以对已存在的Key执行上述操作,就是更新Value值 1 2 3 my_dict1['林' ]=33 print (my_dict1)
删除元素 语法:字典pop(Key) 结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除 1 2 3 score = my_dict1.pop('周' ) print (f"周的分数{score} ,字典中的内容{my_dict1} " )
清空元素 语法:字典.clear() 结果:字典被修改,元素被清空 1 2 3 my_dict1.clear() print (f"字典被清空了{my_dict1} " )
获取全部的key 1 2 3 my_dict1 = {'王' :99 ,'林' :88 ,'周' :99 } print (my_dict1.keys())
统计字典元素数量 遍历字典 1 2 3 4 5 6 7 8 9 for key in my_dict1.keys(): print (f"字典的key是{key} " ) print (f"字典的value是{my_dict1[key]} " ) for key in my_dict1: print (f"字典的key是{key} " ) print (f"字典的value是{my_dict1[key]} " )
数据容器的对比 对比
| | 列表 | 元组 | 字符串 | 集合 | 字典 |
通用操作
功能 描述 通用for循环 遍历容器(字典是遍历key) max 容器内最大元素 min() 容器内最小元素 len() 容器元素个数 list() 转换为列表 tuple() 转换为元组 str() 转换为字符串 set() 转换为集合 sorted(序列, [reverse=True]) 排序,reverse=True表示降序 得到一个排好序的列表
第六章 函数的多返回值 在函数中,执行返回操作后,函数会自动结束,后续代码不再执行,故不能连续书写两条return语句,但在Python中,却能够支持函数有多返回值 1 2 3 4 5 6 7 8 9 10 11 12 def func (a,b ): """ 无法实现多返回 return a+b return a-b """ return a+b,a-b result1,result2 = func(1 ,2 ) print (result1)print (result2)
函数的多种传参 位置参数 定义:调用函数时根据函数定义的参数位置来传递参数。
1 2 3 def user_info (name ,age,gender ): print (f"名字是{name} ,年龄是{age} ,性别是{gender} " ) user_info('韩一' ,18 ,'男' )
关键字参数 定义:函数调用时通过“键=值”形式传递参数.
函数调用时,如果有位置参数时,位置参数必须在关键字参数的前面,但关键字参数之间不存在先后顺序
1 2 3 4 def user_info (name ,age,gender ): print (f"名字是{name} ,年龄是{age} ,性别是{gender} " ) user_info('韩一' ,18 ,'男' ) user_info(age=18 ,name='韩一' ,gender='男' )
缺省参数 定义:在定义函数时,给参数指定一个默认值,具有默认值的参数就叫做缺省参数。
所有位置参数必须出现在默认参数前,包括函数定义和调用,默认值参数在最后。
1 2 3 4 def user_info (name ,age,gender='男' ): print (f"名字是{name} ,年龄是{age} ,性别是{gender} " ) user_info('韩一' ,18 ) user_info('韩二' ,19 ,'女' )
不定长参数 定义:在定义函数时,不确定调用时会传递多少个参数,就可以使用不定长参数。
1 2 3 4 5 6 7 8 9 10 11 12 def user_info (*args ): print (f"args参数的类型是{type (args)} ,内容是{args} " ) user_info('小李' ,18 ) def user_info (**kwargs ): print (f"args参数的类型是{type (kwargs)} ,内容是{kwargs} " ) user_info(name='小李' ,age = 18 )
函数作为参数 可以将函数本身作为参数,传入到另一个函数中使用。 作用:传入计算逻辑,而非传入数据。1 2 3 4 5 6 7 8 def fun_test (computer ): result =computer (1 ,2 ) print (f"computer的类型是{type (computer)} ,结果是{result} " ) def add (x,y ): return x+y fun_test(add)
Lambda匿名函数 语法:lambda 传入参数: 函数体(一行代码)lambda是关键字,表示定义匿名函数; 传入参数表示匿名函数的形式参数,如:x, y表示接收2个形式参数; 函数体,就是函数的执行逻辑 Lambda匿名函数,只能写一行代码,不能写多行代码
1 2 3 4 5 6 def test_function (compute ): result = compute(1 ,2 ) print (f"结果是{result} " ) test_function(lambda x,y: x*y)
第七章 文件编码 1.什么是编码? 2.为什么要编码? 3.编码的作用? 4.编码的分类?
文件的读写操作 文件可以分为文本文件、视频文件、图像文件、可执行文件等多种类别。 文件的操作 打开文件 通常使用open函数来打开文件open(name,mode,encoding)name是要打开的目标文件名的字符串(可以包括文件所在的具体路径) mode是打开文件的模式,即读取、写入、追加等 encoding是指定文件的编码方式(推荐使用UTF-8) 常用的三种基础访问模式: 模式 描述 r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 W 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。 如果该文件不存在,创建新文件。 a 打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后。 如果该文件不存在,创建新文件进行写入。
读取文件 使用read()方法读取文件内容file.read(num)file是文件对象 num表示读取的数据长度(单位是字节),如果没有传入num,那么就是读取所以的数据 使用readline()方法读取文件内容file.readline() readline()方法读取文件的一行内容 使用readlines()方法读取文件内容file.readlines() readlines()方法读取文件的所有内容,返回一个列表,列表的每个元素是文件的一行内容 for循环逐行读取 读取后关闭文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 f = open ("D:Silvan.txt" ,"r" ,encoding="UTF-8" ) print (type (f))print (f.read(1 ))print (f.read())print ("------" )lines = f.readlines() print (f"lines对象的类型是{type (lines)} " )print (lines)line1 = f.readline() line2 = f.readline() line3 = f.readline() print (f"第一行的内容{line1} " )print (f"第二行的内容{line2} " )print (f"第三行的内容{line3} " )for line in f: print (f"每一行的内容是{line} " ) f.close() with open as f: for line in f: print (f"每一行的内容是{line} " )
操作 功能 文件对象 = open(file, mode, encoding) 打开文件获得文件对象 文件对象.read(num) 读取指定长度字节 不指定num读取文件全部 文件对象.readline() 读取一行 文件对象.readlines() 读取全部行,得到列表 for line in 文件对象 for循环文件行,一次循环得到一行数据 文件对象.close() 关闭文件对象 with open() as f 通过with open语法打开文件,可以自动关闭
写入文件 可以通过write()方法将数据写入文件需要注意的是,直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区;当调用flush的时候+内容会真正写入文件;这样做是避免频繁的操作硬盘,导致效率下降(攒一堆,一次性写磁盘)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 """ 演示文件的写入 """ f= open ("E:/word.txt" ,"w" ,encoding="UTF-8" ) f.write("hello" ) f.flush() f.close()
追加写入 追加写入即通过open函数的”a”模式打开文件后,再调用write方法写入内容,追加写入的内容会追加到文件末尾。 a模式,文件不存在时,会创建新文件;文件存在时,会在原有内容后面继续写入;可以使用”\n”来写出换行符 1 2 3 4 5 6 7 8 9 10 11 """ 演示文件的追加 """ f= open ("E:/word.txt" ,"a" ,encoding="UTF-8" ) f.write("hsz" ) f.flush() f.close()