从社会实验到算法 一开始有100个人,每个人都有100元基尼系数会是多少?
首先从一个社会实验开始,该实验的规则看似非常公平,甚至对于0元者还有”优待”,所以乍一眼望去我们会感觉应当随着次数增多,金币的分布会越平均,于是我们编写一个Java程序来模拟这个实验,并计算出这个社会的基尼系数。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 public class Experiment { public static void main (String[] args) { System.out.println("一个社会的基尼系数是一个在0~1之间的小数" ); System.out.println("基尼系数为0代表所有人的财富完全一样" ); System.out.println("基尼系数为1代表有1个人掌握了全社会的财富" ); System.out.println("基尼系数越小,代表社会财富分布越均衡;越大则代表财富分布越不均衡" ); System.out.println("在2022年,世界各国的平均基尼系数为0.44" ); System.out.println("目前普遍认为,当基尼系数到达 0.5 时" ); System.out.println("就意味着社会贫富差距非常大,分布非常不均匀" ); System.out.println("社会可能会因此陷入危机,比如大量的犯罪或者经历社会动荡" ); System.out.println("测试开始" ); int n = 100 ; int t = 1000 ; System.out.println("人数 : " + n); System.out.println("轮数 : " + t); experiment(n, t); System.out.println("测试结束" ); } public static void experiment (int n, int t) { double [] wealth = new double [n]; Arrays.fill(wealth, 100 ); boolean [] hasMoney = new boolean [n]; for (int i = 0 ; i < t; i++) { Arrays.fill(hasMoney, false ); for (int j = 0 ; j < n; j++) { if (wealth[j] > 0 ) { hasMoney[j] = true ; } } for (int j = 0 ; j < n; j++) { if (hasMoney[j]) { int other = j; do { other = (int ) (Math.random() * n); } while (other == j); wealth[j]--; wealth[other]++; } } } Arrays.sort(wealth); System.out.println("列出每个人的财富(贫穷到富有) : " ); for (int i = 0 ; i < n; i++) { System.out.print((int ) wealth[i] + " " ); if (i % 10 == 9 ) { System.out.println(); } } System.out.println(); System.out.println("这个社会的基尼系数为 : " + calculateGini(wealth)); } public static double calculateGini (double [] wealth) { double sumOfAbsoluteDifferences = 0 ; double sumOfWealth = 0 ; int n = wealth.length; for (int i = 0 ; i < n; i++) { sumOfWealth += wealth[i]; for (int j = 0 ; j < n; j++) { sumOfAbsoluteDifferences += Math.abs(wealth[i] - wealth[j]); } } return sumOfAbsoluteDifferences / (2 * n * sumOfWealth); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 一个社会的基尼系数是一个在0~1之间的小数 基尼系数为0代表所有人的财富完全一样 基尼系数为1代表有1个人掌握了全社会的财富 基尼系数越小,代表社会财富分布越均衡;越大则代表财富分布越不均衡 在2022年,世界各国的平均基尼系数为0.44 目前普遍认为,当基尼系数到达 0.5 时 就意味着社会贫富差距非常大,分布非常不均匀 社会可能会因此陷入危机,比如大量的犯罪或者经历社会动荡 测试开始 人数 : 100 轮数 : 100 列出每个人的财富(贫穷到富有) : 80 81 82 84 84 84 85 86 86 87 87 88 89 89 89 90 90 91 91 91 92 92 92 92 92 93 94 94 94 95 95 95 95 96 96 97 97 97 97 97 97 98 98 98 98 98 99 99 99 100 100 100 100 100 100 101 101 101 101 101 101 101 102 102 102 102 102 103 103 103 104 104 104 105 105 105 106 107 107 107 108 108 109 109 110 111 112 113 113 113 116 116 116 119 119 120 120 123 124 131 这个社会的基尼系数为 : 0.056606 测试结束 进程已结束,退出代码为 0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 一个社会的基尼系数是一个在0~1之间的小数 基尼系数为0代表所有人的财富完全一样 基尼系数为1代表有1个人掌握了全社会的财富 基尼系数越小,代表社会财富分布越均衡;越大则代表财富分布越不均衡 在2022年,世界各国的平均基尼系数为0.44 目前普遍认为,当基尼系数到达 0.5 时 就意味着社会贫富差距非常大,分布非常不均匀 社会可能会因此陷入危机,比如大量的犯罪或者经历社会动荡 测试开始 人数 : 100 轮数 : 1000000 列出每个人的财富(贫穷到富有) : 0 1 2 4 4 4 5 6 8 9 9 11 11 11 12 13 13 14 14 16 17 20 20 20 25 26 27 27 28 29 30 30 32 32 34 36 36 37 37 39 41 44 46 47 49 53 53 53 53 55 56 60 63 63 63 72 75 90 92 93 93 94 95 97 97 103 105 108 111 111 112 114 114 121 128 129 136 143 146 151 154 160 170 181 183 189 197 202 227 231 239 272 273 279 304 310 355 419 484 893 这个社会的基尼系数为 : 0.552244 测试结束 进程已结束,退出代码为 0
这是一个乍一看很公平的实验,但实际中,随着模拟的次数越来越多,这个实验的基尼系数会非常高 实验原因 刚开始次数过少,财富差距无法拉开明显差距所以基尼系数很小,但随着次数越来越多,逐渐出现“少数人掌握大量财富,多数人财富微薄甚至为 0” 的格局 关键机制 1:单轮内 “固定支出 + 随机收入” 的不对称,必然产生微小差距 支出端(刚性固定) :只要手里有钱(>0 元),无论你有 100 元还是 1 元,都必须拿出1 元(支出金额与自身财富无关,是 “定额税” 式的强制流出);收入端(完全随机) :所有人拿出的钱(总捐赠额 = 当前非 0 元人数 ×1 元)会随机分给 100 人(包括 0 元者),每人收到的金额可能是 0 元、1 元、2 元…… 最多等于总捐赠额。关键机制 2:多轮 “差距累积效应”,让微小差距滚雪球式放大 单轮的微小差距(如 99 元 vs 101 元),不会因后续轮次 “随机抵消”,反而会复利式累积 财富基数的 “非对称影响”:同样是 1 元的支出 / 收入,对富人(如 200 元)和穷人(如 10 元)的影响天差地别 ——富人支出 1 元,仅减少 0.5% 财富,几乎无影响; 穷人支出 1 元,减少 10% 财富,极易陷入 “财富缩水→变 0 元” 的循环。 关键机制 3:0 元者 “豁免机制”,进一步固化差距 若 0 元者收到 1 元(变成 1 元),下一轮必须支出 1 元;若再没收到收入,又会回到 0 元,陷入 “0 元→1 元→0 元” 的死循环,无法形成财富基数。 非 0 元者的 “优势循环”:财富多的人(如 200 元)几乎不可能变 0 元,能持续参与 “支出 1 元 + 接收收入”—— 即使短期收到 0 元,财富仅从 200→199,仍有足够基数应对后续波动,且有更多机会 “接住” 他人的随机捐赠,财富持续增长。 基尼系数随轮次上升的本质:财富离散度持续扩大
总结:“随机分配”≠“均匀分配”
这个实验的核心启示是:规则的微小不对称,会通过 “累积效应” 被无限放大。 即使初始绝对均匀,只要存在 “固定支出 + 随机收入” 的不对称,以及 “0 元者难以积累” 的机制,随机波动就不会抵消差距,反而会让财富逐渐向少数人集中 —— 这也是现实中 “马太效应”(富者愈富,贫者愈贫)的简化模型。这个实验的目的仅仅是引起对学习算法的兴趣,告诉我们不要以感觉为标准来判断算法,应当认真思考,仔细学习。 选择、冒泡、插入排序 这是算法中最基础的排序方法,也有人叫他们:三傻排序 选择排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static void selectSort (int [] arr) { if (arr ==null || arr.length<2 ){ return ; } int minIndex; int minVal; for (int i=0 ;i<arr.length-1 ;i++){ minIndex = i; minVal = arr[i]; for (int j=i+1 ;j<arr.length;j++){ if (arr[j]<minVal){ minIndex = j; minVal=arr[j]; } } if (minIndex!=i){ swap(arr,i,minIndex); } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public class SelectSort { public static void swap (int [] arr, int i, int j) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } public static int [] randomArray(int n){ int [] array = new int [n]; for (int i=0 ;i<n;i++){ array[i]=(int )(Math.random()*100 ); } return array; } public static void selectSort (int [] arr) { if (arr ==null || arr.length<2 ){ return ; } int minIndex; int minVal = arr[0 ]; for (int i=0 ;i<arr.length-1 ;i++){ minIndex = i; minVal = arr[i]; for (int j=i+1 ;j<arr.length;j++){ if (arr[j]<minVal){ minIndex = j; minVal=arr[j]; } } if (minIndex!=i){ swap(arr,i,minIndex); } } } public static void main (String[] args) { int [] arr = randomArray(10 ); selectSort(arr); for (int i=0 ;i<arr.length;i++){ System.out.print(arr[i]+" " ); } } }
冒泡排序 冒泡排序是一种简单直观的排序算法。它的工作原理是重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。 每次循环从数组前边逐个筛选较大的值放到尾部
代码实现过程:
循环判断后,将大的值放到数组尾部后,便不再判断尾部的值 可以理解为从数组最大的值开始找起,找到最大值后排好,再找下一个最大值,直到数组排序完成 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public static void bubbleSort (int [] arr) { if (arr ==null || arr.length<2 ){ return ; } for (int end=arr.length-1 ;end>0 ;end--){ for (int start=0 ;start<end;start++){ if (arr[start]>arr[start+1 ]){ swap(arr,start,start+1 ); } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class SelectSort { public static void swap (int [] arr, int i, int j) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } public static int [] randomArray(int n){ int [] array = new int [n]; for (int i=0 ;i<n;i++){ array[i]=(int )(Math.random()*100 ); } return array; } public static void bubbleSort (int [] arr) { if (arr ==null || arr.length<2 ){ return ; } for (int end=arr.length-1 ;end>0 ;end--){ for (int start=0 ;start<end;start++){ if (arr[start]>arr[start+1 ]){ swap(arr,start,start+1 ); } } } } public static void main (String[] args) { int [] arr = randomArray(10 ); bubbleSort(arr); for (int i=0 ;i<arr.length;i++){ System.out.print(arr[i]+" " ); } } }
插入排序 1 2 3 4 5 6 7 8 9 10 11 12 13 public static void insertionSort (int [] arr) { if (arr==null ||arr.length==0 ){ return ; } for (int i=0 ;i<arr.length-1 ;i++){ for (int j=i;j>=0 ;j--){ if (arr[j+1 ]<arr[j]){ swap(arr,j,j+1 ); } } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class SelectSort { public static void swap (int [] arr, int i, int j) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } public static int [] randomArray(int n){ int [] array = new int [n]; for (int i=0 ;i<n;i++){ array[i]=(int )(Math.random()*100 ); } return array; } public static void insertionSort (int [] arr) { if (arr==null ||arr.length==0 ){ return ; } for (int i=0 ;i<arr.length-1 ;i++){ for (int j=i;j>=0 ;j--){ if (arr[j+1 ]<arr[j]){ swap(arr,j,j+1 ); } } } } public static void main (String[] args) { int [] arr = randomArray(10 ); insertionSort(arr); for (int i=0 ;i<arr.length;i++){ System.out.print(arr[i]+" " ); } } }
三种排序总结 选择排序:
基本思想 :每一趟从无序区选择最小(或最大)元素,放到有序区的末尾。时间复杂度 :空间复杂度 :O(1)稳定性 :不稳定(可能改变相等元素的相对顺序)特点 :交换次数少(最多 n-1 次交换),但比较次数多; 不管数据有序与否,时间复杂度都一样; 简单直观,但性能比插入排序稍差。 冒泡排序:
基本思想 :通过相邻元素比较并交换,把较大(或较小)的元素逐步“冒泡”到序列的一端。时间复杂度 :最好:O(n)(序列本身有序,只需一次冒泡即可) 最坏:O(n²) 平均:O(n²) 空间复杂度 :O(1)稳定性 :稳定(相邻元素相等时不交换顺序)特点 :思想直观,常用于入门讲解; 效率较低,数据量大时不推荐。 插入排序:
基本思想 :把序列分为有序区和无序区,每次将无序区的第一个元素插入到有序区合适的位置。时间复杂度 :最好:O(n)(原本接近有序时) 最坏:O(n²) 平均:O(n²) 空间复杂度 :O(1)(原地排序)稳定性 :稳定(相等元素不会交换顺序)特点 :简单,适合数据量小或基本有序的情况; 插入过程像整理扑克牌。 二分搜索 在有序数组中确定num存在还是不存在 在有序数组中找>=num的最左位置 在有序数组中找<=num的最右位置 二分搜索不一定发生在有序数组上(比如寻找峰值问题) 链表入门题 单双链表及其反转 按值传递,按引用传递 一般基本数据类型默认是按值传递,函数会获得参数的副本,修改副本不会修改原始值 引用数据类型默认为按引用传递,在函数中的操作会直接影响原始值 C和C++可以通过传递指针来使函数在修改副本的同时也修改原始值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 public class Main { public static void main (String[] args) { int a = 10 ; f(a); System.out.println(a); Number b = new Number (5 ); g1(b); System.out.println(b.val); g2(b); System.out.println(b.val); int [] c = { 1 , 2 , 3 , 4 }; g3(c); System.out.println(c[0 ]); g4(c); System.out.println(c[0 ]); } public static void f (int a) { a = 0 ; } public static class Number { public int val; public Number (int v) { val = v; } } public static void g1 (Number b) { b = null ; } public static void g2 (Number b) { b.val = 6 ; } public static void g3 (int [] c) { c = null ; } public static void g4 (int [] c) { c[0 ] = 100 ; } public static class ListNode { public int val; public ListNode next; public ListNode (int val) { this .val = val; } public ListNode (int val, ListNode next) { this .val = val; this .next = next; } } }
实现链表反转 假设一个链表的指向为: 11->22->33->44->55 反转后效果则为: 55->44->33->22->11 构造函数原型首先函数必须有一个参数,这个参数就是链表的头结点 其次,函数还应当有返回值,返回值就是反转后的链表头结点 我们可以使用堆栈的方式来实现链表反转 题目链接:https://leetcode.cn/problems/reverse-linked-list/ 反转链表实现: 从头结点开始,先将当前节点的下一个结点的位置用一个变量暂存起来(因为等会修改下一个节点的位置,不存储起来会导致链表断连) 然后修改当前节点的下一个结点为前一个结点(即使是单链表也可以,因为前一个节点是每次实现反转后,将当前结点存在前一个结点,存完后再向后移动链表) 让前一个结点等于当前结点(这就是上一步说的更新节点,链表反转后并后移以后,当前结点就是前结点) 将当前结点后移,进行下一轮循环 循环结束后,返回的是pre节点,这是反转后链表的头结点,不是head因为此时在循环的最后一步,head会移动到链表末尾,指向NULL 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public static class ListNode { public int val; public ListNode next; public ListNode (int val) { this .val = val; } public ListNode (int val, ListNode next) { this .val = val; this .next = next; } } class Solution { public static ListNode reverseList (ListNode head) { ListNode pre = null ; ListNode next = null ; while (head != null ) { next = head.next; head.next = pre; pre = head; head = next; } return pre; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public static class DoubleListNode { public int value; public DoubleListNode last; public DoubleListNode next; public DoubleListNode (int v) { value = v; } } public static DoubleListNode reverseDoubleList (DoubleListNode head) { DoubleListNode pre = null ; DoubleListNode next = null ; while (head != null ) { next = head.next; head.next = pre; head.last = next; pre = head; head = next; } return pre; }
合并两个有序链表 要求:将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。 合并链表实现:
先判断两个有序链表谁的头结点更小,将头结点小的结点作为合并后的链表的头结点。 分别定义两个指针cur1和cur2,一个连接在头结点小的那个结点的下一个结点上,一个连接在头结点较大的那个结点上,假设此题选第一个链表的1作为头结点,那么cur1将指向2,cur2将指向第二个链表的1,并设置pre作为前驱结点,pre指向第一步比较中较小的那个结点 定义循环,循环的结束条件是有一条链表的元素全部遍历完 在循环中,不断比较cur1和cur2的值,将较小的值连接到新的链表上,并向后移动移动对应指针,更新pre的值为当前较小的结点,并继续循环 当循环结束时,直接将另一条有元素未比较的链表的剩余元素链接到新的链表上,因为链表是有序的,所以直接链接即可 返回新链表头结点 测试连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution { public static ListNode mergeTwoLists (ListNode head1, ListNode head2) { if (head1 == null || head2 == null ) { return head1 == null ? head2 : head1; } ListNode head = head1.val <= head2.val ? head1 : head2; ListNode cur1 = head.next; ListNode cur2 = head == head1 ? head2 : head1; ListNode pre = head; while (cur1 != null && cur2 != null ) { if (cur1.val <= cur2.val) { pre.next = cur1; cur1 = cur1.next; } else { pre.next = cur2; cur2 = cur2.next; } pre = pre.next; } pre.next = cur1 != null ? cur1 : cur2; return head; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution { public ListNode mergeTwoLists (ListNode list1, ListNode list2) { if (list1==null ||list2==null ) return list1==null ?list2:list1; ListNode head = list1.val>list2.val ? list2:list1; ListNode cur1=head.next; ListNode cur2= head==list1?list2:list1; ListNode pre=head; while (cur1!=null &&cur2!=null ){ if (cur1.val<cur2.val){ pre.next=cur1; cur1=cur1.next; } else { pre.next=cur2; cur2=cur2.next; } pre=pre.next; } pre.next=cur1==null ?cur2:cur1; return head; } }
两个链表相加 实际上就是利用链表实现高精度算法的加法 它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储一位数字 题目链接: 链表相加实现: 创建一个ans结点,该结点只用来作为结果链表的头结点返回 创建一个cur结点,该结点来记录当前操作位置,每次计算更新位置 创建一个进位变量carry,记录当前位相加的结果是否超过10,超过则进位 定义循环,每次循环移动两条链表到下一位,链表的结束条件为两条链表都为空 在循环中,直接计算两个链表数值相加的结果,并分别记录下结果的个位和十位 判断是否为第一次计算,如果是第一次计算,则将cur指向ans结点,如果不是则将cur指向下一个结点 不断循环,直到两条链表都为空 最后跳出循环后,如果carry为1,则再创建一个数值为1的结点,并添加到链表末尾 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 public class Main { public static class ListNode { public int val; public ListNode next; public ListNode (int val) { this .val = val; } public ListNode (int val, ListNode next) { this .val = val; this .next = next; } } static class Solution { public static ListNode addTwoNumbers (ListNode h1, ListNode h2) { ListNode ans = null , cur = null ; int carry = 0 ; for (int sum, val; h1 != null || h2 != null ; h1 = h1 == null ? null : h1.next, h2 = h2 == null ? null : h2.next ) { sum = (h1 == null ? 0 : h1.val) + (h2 == null ? 0 : h2.val) + carry; val = sum % 10 ; carry = sum / 10 ; if (ans == null ) { ans = new ListNode (val); cur = ans; } else { cur.next = new ListNode (val); cur = cur.next; } } if (carry == 1 ) { cur.next = new ListNode (1 ); } return ans; } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 class Solution { public ListNode addTwoNumbers (ListNode l1, ListNode l2) { ListNode ans=null ; ListNode cur=null ; int carry=0 ; for (int sum,val; l1!=null ||l2!=null ; l1=l1==null ?null :l1.next, l2=l2==null ?null :l2.next){ sum=(l1==null ?0 :l1.val)+(l2==null ?0 :l2.val)+carry; val=sum%10 ; carry=sum/10 ; if (ans==null ){ ans= new ListNode (val); cur=ans; } else { cur.next=new ListNode (val); cur=cur.next; } } if (carry!=0 ){ cur.next=new ListNode (carry); } return ans; } }
划分链表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 public class Main { public static class ListNode { public int val; public ListNode next; public ListNode (int val) { this .val = val; } public ListNode (int val, ListNode next) { this .val = val; this .next = next; } } static class Solution { public static ListNode partition (ListNode head, int x) { ListNode leftHead = null , leftTail = null ; ListNode rightHead = null , rightTail = null ; ListNode next = null ; while (head != null ) { next = head.next; head.next = null ; if (head.val < x) { if (leftHead == null ) { leftHead = head; } else { leftTail.next = head; } leftTail = head; } else { if (rightHead == null ) { rightHead = head; } else { rightTail.next = head; } rightTail = head; } head = next; } if (leftHead == null ) { return rightHead; } leftTail.next = rightHead; return leftHead; } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 class Solution { public ListNode partition (ListNode head, int x) { ListNode leftHead=null ,leftTail=null ,rightHead=null ,rightTail=null ; ListNode next=null ; while (head!=null ){ next=head.next; head.next=null ; if (head.val<x){ if (leftHead==null ) leftHead=head; else leftTail.next=head; leftTail=head; } else { if (rightHead==null ) rightHead=head; else rightTail.next=head; rightTail=head; } head=next; } if (leftHead==null ) return rightHead; leftTail.next=rightHead; return leftHead; } }
队列和栈 队列:先进先出 栈:先进后出使用链表和数组实现 使用链表实现队列:
这里直接使用Java内部提供的双端链表实现的队列1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public static class Queue1 { public Queue<Integer> queue = new LinkedList <>(); public boolean isEmpty () { return queue.isEmpty(); } public void offer (int num) { queue.offer(num); } public int poll () { return queue.poll(); } public int peek () { return queue.peek(); } public int size () { return queue.size(); } }
使用数组实现队列:
前提是该队列最大长度是固定的,即数组的长度是固定的 不要求队列的头部必须待在数组头部,可以待在数组的任意位置 实际刷题时更常见的写法,因为常数时间好,且一般笔试、面试都会有一个明确数据量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public static class Queue2 { public int [] queue; public int l; public int r; public Queue2 (int n) { queue = new int [n]; l = 0 ; r = 0 ; } public boolean isEmpty () { return l == r; } public void offer (int num) { queue[r++] = num; } public int poll () { return queue[l++]; } public int head () { return queue[l]; } public int tail () { return queue[r - 1 ]; } public int size () { return r - l; } }
使用数组实现栈:链表实现的栈Java内部已经提供了,不过常数时间不太好 前提依旧是最大长度固定 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public static class Stack2 { public int [] stack; public int size; public Stack2 (int n) { stack = new int [n]; size = 0 ; } public boolean isEmpty () { return size == 0 ; } public void push (int num) { stack[size++] = num; } public int pop () { return stack[--size]; } public int peek () { return stack[size - 1 ]; } public int size () { return size; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class MyCircularQueue { public int [] queue; public int l, r, size, limit; public MyCircularQueue (int k) { queue = new int [k]; l = r = size = 0 ; limit = k; } public boolean enQueue (int value) { if (isFull()) { return false ; } else { queue[r] = value; r = r == limit - 1 ? 0 : (r + 1 ); size++; return true ; } } public boolean deQueue () { if (isEmpty()) { return false ; } else { l = l == limit - 1 ? 0 : (l + 1 ); size--; return true ; } } public int Front () { if (isEmpty()) { return -1 ; } else { return queue[l]; } } public int Rear () { if (isEmpty()) { return -1 ; } else { int last = r == 0 ? (limit - 1 ) : (r - 1 ); return queue[last]; } } public boolean isEmpty () { return size == 0 ; } public boolean isFull () { return size == limit; } }
栈和队列相互实现 使用栈实现队列 仅仅需要两个栈即可实现,一个栈叫做in,一个栈叫做out,in栈用来接收数据,out栈用来输出数据,倒数据时严格遵循两点要求out栈为空时,才能倒数据到out栈 一旦倒数据,in栈必须一下倒完,不能有数据留在in栈中 测试链接 : https://leetcode.cn/problems/implement-queue-using-stacks/ 实现流程: 先对两个栈进行初始化,使用泛型时,要记住使用引用数据类型 接着编写in栈倒数据到out栈的方法,这个方法十分重要,应当实现当out栈为空时,将in栈的数据倒入out栈中,当out栈不为空则不进行操作 编写入队的push方法时,直接将数据push到in栈中即可,另外要在push方法后调用inToOut()方法,在out栈为空的时候,将in栈的数据倒到out栈中,防止数据一直堆积在in栈中 编写pop方法时,要先调用inToOut()方法,确保out栈中没数据的时候,及时从in栈中获取,然后返回out栈的栈顶元素 编写peek方法时,要先调用inToOut()方法,确保out栈中没数据的时候,及时从in栈中获取,然后返回out栈的栈顶元素 编写empty方法时,即可以判断in栈和out栈是否都为空,也可以先调用inToOut()方法,再判断out栈是否为空 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class MyQueue { public Stack<Integer> in; public Stack<Integer> out; public MyQueue () { in = new Stack <Integer>(); out = new Stack <Integer>(); } private void inToOut () { if (out.empty()) { while (!in.empty()) { out.push(in.pop()); } } } public void push (int x) { in.push(x); inToOut(); } public int pop () { inToOut(); return out.pop(); } public int peek () { inToOut(); return out.peek(); } public boolean empty () { return in.isEmpty() && out.isEmpty(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 class MyQueue { public Stack<Integer> in; public Stack<Integer> out; public MyQueue () { in= new Stack <Integer>(); out= new Stack <Integer>(); } public void inToOut () { if (out.empty()){ while (!in.empty()){ out.push(in.pop()); } } } public void push (int x) { in.push(x); inToOut(); } public int pop () { inToOut(); return out.pop(); } public int peek () { inToOut(); return out.peek(); } public boolean empty () { inToOut(); return out.empty(); } }
使用队列实现栈 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class MyStack { Queue<Integer> queue; public MyStack () { queue = new LinkedList <Integer>(); } public void push (int x) { int n = queue.size(); queue.offer(x); for (int i = 0 ; i < n; i++) { queue.offer(queue.poll()); } } public int pop () { return queue.poll(); } public int top () { return queue.peek(); } public boolean empty () { return queue.isEmpty(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class MyStack { public Queue<Integer> queue; public MyStack () { queue=new LinkedList <Integer>(); } public void push (int x) { int n=queue.size(); queue.offer(x); for (int i=0 ;i<n;i++){ queue.offer(queue.poll()); } } public int pop () { return queue.poll(); } public int top () { return queue.peek(); } public boolean empty () { return queue.isEmpty(); } }
栈的入门题目——最小栈 栈的入门题目,要求实现一个栈,并且实现一个getmin()方法,要求时间复杂度为O(1),因此不能依靠遍历获得最小值 测试链接 : https://leetcode.cn/problems/min-stack/ 最小栈实现思路: 使用两个栈,一个栈用于存储数据,一个栈用于存储最小值 每次在数据栈中添加元素时,比较新添数据和最小栈的栈顶哪个更小,将更小的数据重新压入最小栈,一直保持数据栈和最小栈的数量一致 每次删除数据时,同步删除最小栈的栈顶数据 每次获取最小值时,直接返回最小栈的栈顶数据 因为前面提到的内置栈的常数时间复杂度较慢,所以这里两种方式的栈都记录一下1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 class MinStack { public Stack<Integer> data; public Stack<Integer> min; public MinStack () { data = new Stack <Integer>(); min = new Stack <Integer>(); } public void push (int val) { data.push(val); if (min.isEmpty()||val<min.peek()){ min.push(val); } else min.push(min.peek()); } public void pop () { data.pop(); min.pop(); } public int top () { return data.peek(); } public int getMin () { return min.peek(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 class MinStack { public final int Max=10001 ; public int [] data; public int [] min; int size; public MinStack () { data = new int [Max]; min = new int [Max]; size=0 ; } public void push (int val) { data[size]=val; if (size==0 ||val<=min[size-1 ]) min[size]=val; else min[size]=min[size-1 ]; size++; } public void pop () { size--; } public int top () { return data[size-1 ]; } public int getMin () { return min[size-1 ]; } }
双端队列 二叉树 二叉树的遍历 二叉树的遍历,分为前序、中序、后序、层序遍历,这里主要记录二叉树的三序遍历前序遍历:先遍历根节点,再遍历左子树,最后遍历右子树 中序遍历:先遍历左子树,再遍历根节点,最后遍历右子树 后序遍历:先遍历左子树,再遍历右子树,最后遍历根节点 层序遍历:按照层的顺序遍历,即先遍历根节点,再遍历左右子树,最后遍历左右子树的子节点 二叉树的三序遍历有递归和非递归两种方式,任何一种递归的方式都可以转换为非递归方式,因此这里主要记录一下递归方式 递归遍历 二叉树的遍历实现思路:
创建一个函数,在函数中,如果当前节点为空则退出 接着先序遍历则优先打印当前结点的值,接着递归调用该函数,此时传入的值为当前节点的左子树,接着调用函数传入当前结点的右子树 中序后序的区别仅仅是打印和递归调用的顺序不同 递归序:
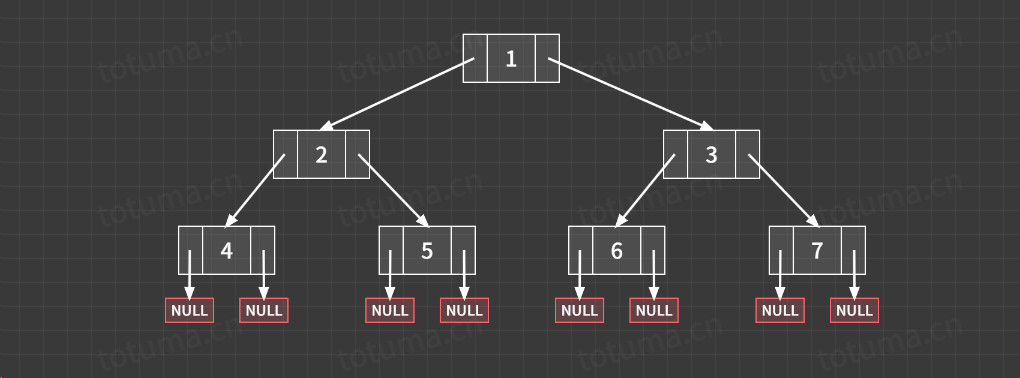
1->2->4->4->4->2->5->5->5->2-> 1->3->6->6->6->3->7->7->7->3-> 1 递归序即为在递归过程中访问的顺序,不难发现,只要一个结点不为空结点,那么一定会访问三次,而三种遍历方式,控制的就是他是在哪次访问的时候输出当前结点的值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public class test { public static class TreeNode { public int val; public TreeNode left; public TreeNode right; public TreeNode (int x) { this .val = x; } } public static void preTraversal (TreeNode head) { if (head==null ){ return ; } System.out.print(head.val+" " ); preTraversal(head.left); preTraversal(head.right); } public static void inTraversal (TreeNode head) { if (head==null ){ return ; } inTraversal(head.left); System.out.print(head.val+" " ); inTraversal(head.right); } public static void afterTraversal (TreeNode head) { if (head==null ){ return ; } afterTraversal(head.left); afterTraversal(head.right); System.out.print(head.val+" " ); } public static void main (String[] args) { TreeNode head = new TreeNode (1 ); head.left = new TreeNode (2 ); head.right = new TreeNode (3 ); head.left.left = new TreeNode (4 ); head.left.right = new TreeNode (5 ); head.right.left = new TreeNode (6 ); head.right.right = new TreeNode (7 ); System.out.println("先序遍历结果: " ); preTraversal(head); System.out.println(); System.out.println("中序遍历结果: " ); inTraversal(head); System.out.println(); System.out.println("后序遍历结果: " ); afterTraversal(head); } }
非递归遍历 先序遍历 用栈实现二叉树的先序遍历思路: 实现思路:判断当前节点是否为空,不为空时则将结点压入栈 接着循环遍历栈,循环条件为栈不为空,循环过程中先弹出一个结点,此时应当记录一下该结点 输出弹出的那个结点的值 因为栈是先进后出,所以应当先判断是否有右子树,有则将右子树入栈,无则判断是否有左子树,有则将左子树入栈,无则退出此次循环 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public static void preOrder (TreeNode head) { if (head==null ){ return ; } Stack<TreeNode> stack = new Stack <>(); stack.push(head); while (!stack.isEmpty()){ TreeNode node = stack.pop(); System.out.print(node.val+" " ); if (node.right!=null ){ stack.push(node.right); } if (node.left!=null ){ stack.push(node.left); } } System.out.println(); }
中序遍历 用栈实现二叉树的中序遍历思路:将树的左边界依次进栈,直到左边界全部压入栈中 接着将栈里元素弹出,打印该结点并将弹出结点的右树重复执行上一个步骤直到栈为空 测试链接:https://leetcode.cn/problems/binary-tree-inorder-traversal/ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static void inOrder(TreeNode head){ if (head==null ){ return ; } Stack <TreeNode> stack = new Stack <>(); while (!stack .isEmpty()||head!=null ){ if (head!=null ){ stack .push(head); head = head.left; } else { head = stack .pop(); System.out.print(head.val+" " ); head = head.right; } } System.out.println(); }
后序遍历 后续遍历有两种实现方法,一种是使用两个栈来实现,另一种是使用一个栈加上哨兵记录栈内结点来实现 非递归的后序遍历事实上和先序遍历一样,只是将左右子树顺序交换一下后再倒过来输出。先序是中->左->右,交换位置后是中->右->左,再倒过来输出就是后序:左->右->中 类似两个栈实现队列的思路,通过两个栈来实现后序遍历 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public static void postOrder (TreeNode head) { if (head==null ){ return ; } Stack<TreeNode> in = new Stack <>(); Stack<TreeNode> out = new Stack <>(); in.push(head); TreeNode node; while (!in.isEmpty()){ node = in.pop(); out.push(node); if (node.left!=null ){ in.push(node.left); } if (node.right!=null ){ in.push(node.right); } } while (!out.isEmpty()){ System.out.print(out.pop().val+" " ); } System.out.println(); }
总结 递归方法遍历二叉树,前面分析了每个结点都会访问三次,所以时间复杂度是O(n),非递归方法每个结点也都会进栈和出栈,时间复杂度也是O(n) 不管是递归还是非递归,空间复杂度都是O(h),此处h为树的高度 两个栈实现后序遍历的方法,非常好写且容易理解但不推荐,因为他要一下收集全部的结点,最后逆序输出,额外的空间复杂度为O(N),很浪费空间。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 import java.util.Stack;public class test { public static class TreeNode { public int val; public TreeNode left; public TreeNode right; public TreeNode (int x) { this .val = x; } } public static void preTraversal (TreeNode head) { if (head==null ){ return ; } System.out.print(head.val+" " ); preTraversal(head.left); preTraversal(head.right); } public static void inTraversal (TreeNode head) { if (head==null ){ return ; } inTraversal(head.left); System.out.print(head.val+" " ); inTraversal(head.right); } public static void afterTraversal (TreeNode head) { if (head==null ){ return ; } afterTraversal(head.left); afterTraversal(head.right); System.out.print(head.val+" " ); } public static void preOrder (TreeNode head) { if (head==null ){ return ; } Stack<TreeNode> stack = new Stack <>(); stack.push(head); while (!stack.isEmpty()){ TreeNode node = stack.pop(); System.out.print(node.val+" " ); if (node.right!=null ){ stack.push(node.right); } if (node.left!=null ){ stack.push(node.left); } } System.out.println(); } public static void inOrder (TreeNode head) { if (head==null ){ return ; } Stack<TreeNode> stack = new Stack <>(); while (!stack.isEmpty()||head!=null ){ if (head!=null ){ stack.push(head); head = head.left; } else { head = stack.pop(); System.out.print(head.val+" " ); head = head.right; } } System.out.println(); } public static void postOrder (TreeNode head) { if (head==null ){ return ; } Stack<TreeNode> in = new Stack <>(); Stack<TreeNode> out = new Stack <>(); in.push(head); TreeNode node; while (!in.isEmpty()){ node = in.pop(); out.push(node); if (node.left!=null ){ in.push(node.left); } if (node.right!=null ){ in.push(node.right); } } while (!out.isEmpty()){ System.out.print(out.pop().val+" " ); } System.out.println(); } public static void main (String[] args) { TreeNode head = new TreeNode (1 ); head.left = new TreeNode (2 ); head.right = new TreeNode (3 ); head.left.left = new TreeNode (4 ); head.left.right = new TreeNode (5 ); head.right.left = new TreeNode (6 ); head.right.right = new TreeNode (7 ); System.out.println("递归先序遍历结果: " ); preTraversal(head); System.out.println(); System.out.println("递归中序遍历结果: " ); inTraversal(head); System.out.println(); System.out.println("递归后序遍历结果: " ); afterTraversal(head); System.out.println(); System.out.println("非递归先序遍历结果: " ); preOrder(head); System.out.println("非递归中序遍历结果: " ); inOrder(head); System.out.println("非递归后序遍历结果: " ); postOrder(head); } }
1 2 3 4 5 6 7 8 9 10 11 12 先序遍历结果: 1 2 4 5 3 6 7 中序遍历结果: 4 2 5 1 6 3 7 后序遍历结果: 4 5 2 6 7 3 1 非递归先序遍历结果: 1 2 4 5 3 6 7 非递归中序遍历结果: 4 2 5 1 6 3 7 非递归后序遍历结果: 4 5 2 6 7 3 1
递归和master公式 递归 递归的底层是利用系统栈实现的,递归的实现原理 :每次递归调用都会将当前调用的参数保存在系统栈中,当递归调用返回时,系统栈中的参数会依次出栈,并返回给调用者。 任何的递归都可以用非递归实现 ,但非递归实现不一定比递归快,改为非递归的好处是不用系统栈空间,系统栈空间相比内存栈空间更宝贵。递归该非递归的必要性:工程上几乎一定要改,除非确定数据量再大,递归也一定不深,例如归并排序,快速排序,线段树等应用 算法题中能通过就不用改。 Master公式 所有子问题规模相同的递归才能用Master公式:T(n) = a*T(n/b) + O(Nc )a:子问题的数量 n/b:每个子问题的规模 O(Nc ):除了子问题调用外的时间复杂度 如果log(b,a) < c, 复杂度为O(Nc ) 如果log(b,a) > c, 复杂度为O(n^log(b,a)) 如果log(b,a) = c, 复杂度为O(n^c*log(n)) 归并算法 归并排序 归并排序的核心过程是:做部分排好序、右部分排好序,利用merge过程让左右整体有序 merge过程:谁小拷贝谁,直到两边的数字全部拷贝完,最后将排好序的数组拷贝回原数组 归并排序有递归实现和非递归实现 时间复杂度为O(n*logn) 需要辅助数组,空间复杂度为O(n) 归并排序为什么速度更快?因为比较行为没有浪费
归并思路:
定义两个指针,分别指向两个有序数组的起始位置 定义一个辅助数组,用于保存排序后的结果 判断两个指针指向的元素大小,将较小的元素拷贝到辅助数组中,并移动指针,直到某一个数组的指针移动到末尾 将剩余的元素拷贝到辅助数组中 将辅助数组拷贝回原数组1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static void merge (int l, int m, int r) { int i = l; int a = l; int b = m + 1 ; while (a <= m && b <= r) { help[i++] = arr[a] <= arr[b] ? arr[a++] : arr[b++]; } while (a <= m) help[i++] = arr[a++]; while (b <= r) help[i++] = arr[b++]; for (i = l; i <= r; i++) arr[i] = help[i]; }
递归实现 递归思路: 首先将数组定义在全局域中,方便递归调用 传入两个参数,分别为需要排序的数组的起始位置和结束位置 判断这两个参数是否相等,如果相等则直接返回,因为一个数天然有序 算出中间位置,将数组分为左右两个部分,分别对左右两个部分进行递归调用,进行排序 归并两个数组,使数组有序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void mergeSort1 (int l, int r) { if (l == r) { return ; } int m = (l + r) / 2 ; mergeSort1(l, m); mergeSort1(m + 1 , r); merge(l, m, r); }
非递归实现 非递归思路 定数组长度 :假设数组有 n 个元素。设置子数组的初始大小 :从 1 开始(每次把相邻的两个“长度为1的数组”合并),然后依次翻倍:第一次合并长度为 1 的小段 第二次合并长度为 2 的小段 第三次合并长度为 4 的小段 …直到子数组大小 ≥ n,排序完成。 合并过程 每一轮从数组的起始位置开始,以当前子数组大小 size 为单位,把相邻的两段有序子数组 进行合并。 合并时要小心边界:如果最后一段不足 size,就直接并到前一段;如果整个区间不足两段,保持不变。举例: 数组 [5, 2, 8, 6, 3, 7, 4, 1]
第一轮(size = 1):把 [5] 和 [2] 合并 → [2, 5],然后 [8] 和 [6] → [6, 8],依次类推。
第二轮(size = 2):把 [2, 5] 和 [6, 8] 合并 → [2, 5, 6, 8],再处理后面几段。
第三轮(size = 4):继续合并更大的有序段。
最终得到完全有序的数组。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public static void mergeSort2 () { for (int l, m, r, step = 1 ; step < n; step <<= 1 ) { l = 0 ; while (l < n) { m = l + step - 1 ; if (m + 1 >= n) { break ; } r = Math.min(l + (step << 1 ) - 1 , n - 1 ); merge(l, m, r); l = r + 1 ; } } }
总结 递归版归并排序的思路是先拆分再合并, 非递归实现则是反过来——从最小的子数组开始逐步合并,直到整个数组有序。 递归实现:优点是代码简洁直观,可读性好 缺点是递归会消耗一定的栈空间,遇到特别大的数组时可能会超出栈空间限制 非递归实现:优点是避免栈空间溢出的问题,不依赖系统调用栈,内存更可控 缺点是代码复杂度高,且逻辑不如递归直观,程序可读性更差 选择建议:学习、普通场景、小规模排序 → 推荐 递归实现,简单直接。 工程实践、大规模数据、内存受限场景 → 推荐 非递归实现,更稳健。归并分治 随机快速排序 随机快排的核心思想是递归分治,非递归快排能够实现但不常见先把数组划分为两部分 再分别对这两部分递归排序 最终合并 要排序数组 [5, 2, 8, 6, 3]:
随机选一个枢轴,比如随机选到 6 划分:小于等于 6 的放左边 → [5, 2, 3] 大于 6 的放右边 → [8] 枢轴 6 在中间 得到 [5, 2, 3] | 6 | [8] 递归排序 [5, 2, 3] → 得到 [2, 3, 5] 排序思路:在数组中随机选择一个下标,将下标对应的数记为标准x,将数组分为两部分,小于标准数,大于标准数 划分为两部分后,记录下这两部分的边界位置,小于x的便捷位置为first,大于x的边界位置为last 使用临时变量left和right分别记录下边界位置,此时left和right分别指向小于x的边界位置和大于x的边界位置,left和right之前的数均为x,left之前的数都小于x,right之后的数都大于x 递归调用 函数,对小于x的边界位置和大于x的边界位置进行排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public static void quickSort (int l, int r) { if (l >= r) { return ; } int x = arr[l + (int ) (Math.random() * (r - l + 1 ))]; partition(l, r, x); int left = first; int right = last; quickSort(l, left - 1 ); quickSort(right + 1 , r); }
划分思路:已知数组中一定有x这个数 设置两个边界,左边界为left,右边界为right,左边界作为小于x的边界值,右边界作为大于x的边界值 同时用变量i来记录当前操作的下标 设置循环,结束条件为i超出数组的边界 判断当前arr[i]与x的大小关系arr[i] < x,则将arr[i]和arr[left]交换位置,left++,i++ arr[i] > x,则将arr[i]和arr[right]交换位置,right— arr[i] == x,则i++,继续判断下一个数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static void partition (int l, int r, int x) { first = l; last = r; int i = l; while (i <= last) { if (arr[i] == x) { i++; } else if (arr[i] < x) { swap(first++, i++); } else { swap(i, last--); } } }
测试链接 : https://www.luogu.com.cn/problem/P1177
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.io.OutputStreamWriter;import java.io.PrintWriter;import java.io.StreamTokenizer;public class Main { public static int MAXN = 100001 ; public static int [] arr = new int [MAXN]; public static int n; public static void main (String[] args) throws IOException { BufferedReader br = new BufferedReader (new InputStreamReader (System.in)); StreamTokenizer in = new StreamTokenizer (br); PrintWriter out = new PrintWriter (new OutputStreamWriter (System.out)); in.nextToken(); n = (int ) in.nval; for (int i = 0 ; i < n; i++) { in.nextToken(); arr[i] = (int ) in.nval; } quickSort(0 , n - 1 ); for (int i = 0 ; i < n - 1 ; i++) { out.print(arr[i] + " " ); } out.println(arr[n - 1 ]); out.flush(); out.close(); br.close(); } public static void swap (int i, int j) { int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp; } public static void quickSort (int l, int r) { if (l >= r) { return ; } int x = arr[l + (int ) (Math.random() * (r - l + 1 ))]; partition(l, r, x); int left = first; int right = last; quickSort(l, left - 1 ); quickSort(right + 1 , r); } public static int first, last; public static void partition (int l, int r, int x) { first = l; last = r; int i = l; while (i <= last) { if (arr[i] == x) { i++; } else if (arr[i] < x) { swap(first++, i++); } else { swap(i, last--); } } } }
随机选择算法 随机选择算法(Randomized Select),一般是指 快速选择算法(QuickSelect) 的随机化版本,用来在无序数组中找第 k 大的元素。这里的是第k大的元素,不是第k大的不同的元素,因此元素是可以重复数的 时间复杂度为O(n)
实现思路:
随机选择一个数作为基准数来划分数组,根据这个基准数将数组分为3个部分,小于基准数,等于基准数,大于基准数 根据划分的结果,来决定继续在左边还是右边递归查找 只需要处理一边的子数组,所以时间复杂度相比快排更小 堆结构和堆排序